ROLLUP
rollup相对于简单的分组合计增加了小计和合计(适用于统计功能),解释起来会比较抽象,下面我们来看看具体事例。
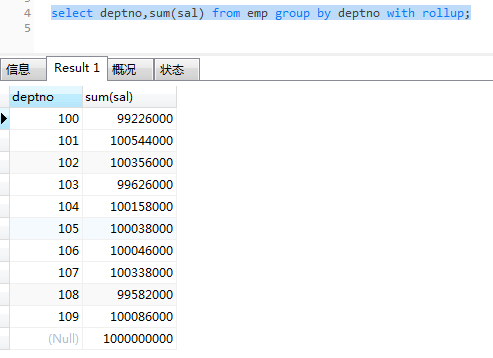
1.统计不同部门工资的总和和所有部门工资的总和。
select deptno,sum(sal) from emp group by deptno with rollup;
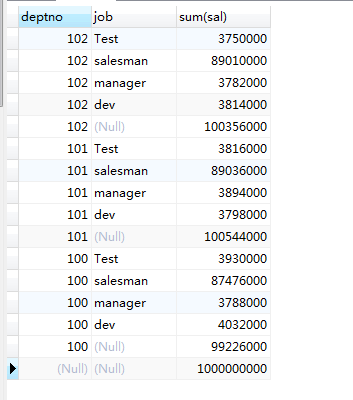
2.先对deptno进行分组,再对job进行分组
select deptno,job,sum(sal) from emp group by deptno,job with rollup;

这里可能就有人会有疑问了,为什么数据比原来多了10条,理论上应该只是全部的总结,只会比group by 多一条数据才合理,查了资料才弄明白,对于聚合单数据(group by 后面的变量一个为单数据,多个则为多数据)是适合的,但是在多数据的情况下就不一样了,下面我们分析一下,首先会根据depno变量,将原始数据分为9个101,102,103...109九个组,group by WITH ROLLUP会在每个分组后面加上本组类的信息(deptno),第5行数据就是1,2,3,4行数据聚合所执行sum(sal)所得的结果,依次类推...108,109也是一样,同时在最后,会将全部的分组聚合。
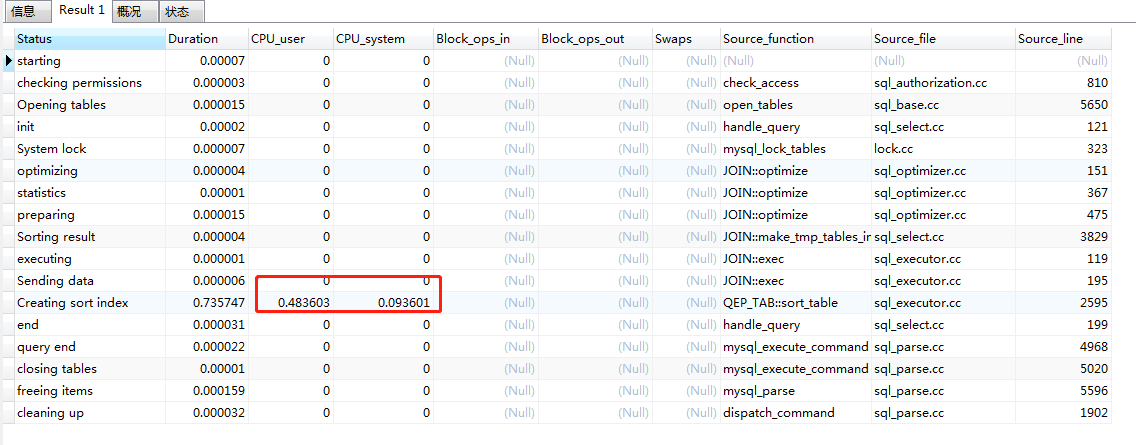
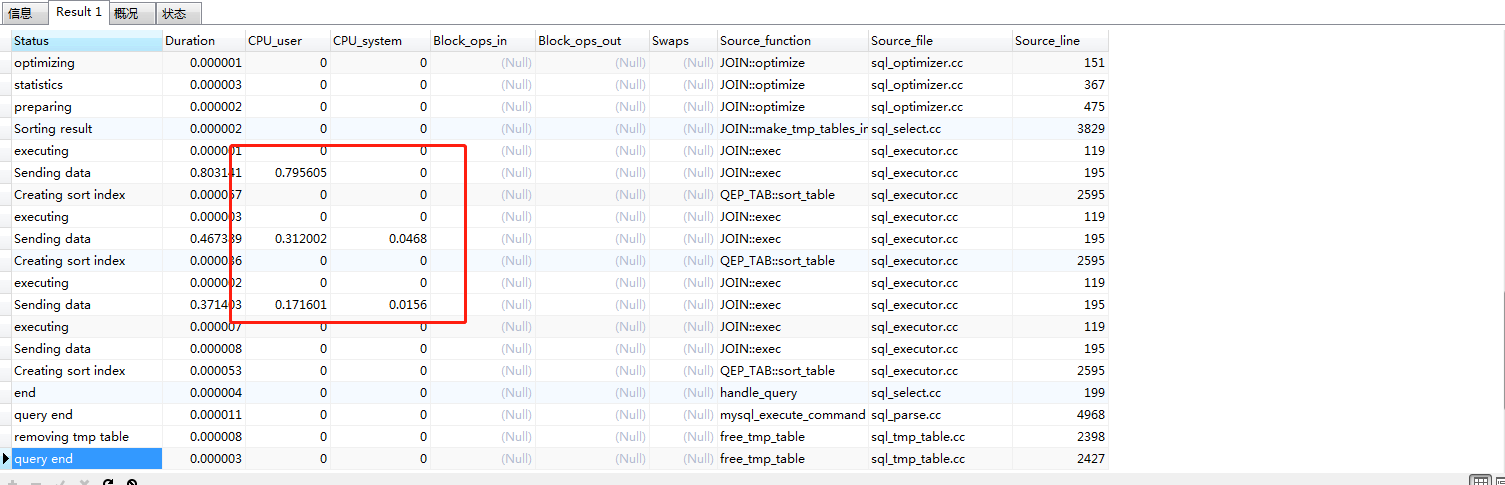
性能分析:
3.对比不使用 rollup实现类似功能(可用UNION ALL语句)
#实现单个部门,单个工种的工资的总和select deptno,job,sum(sal) from emp group by deptno,jobunion all#实现单个部门工资的总和select deptno,null,sum(sal) from emp group by deptnounion all#实现所有部门工资的总和select null,null,sum(sal) from emporder by deptno desc,job desc
性能分析:
总结:
通过2,3执行结果的性能分析:不难看出,相同的功能实现,ROLLUP相对于UNION ALL效率有了极大的提升。
实战案例:
#emp 表结构CREATE TABLE `emp` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `empno` mediumint(8) unsigned NOT NULL DEFAULT '0', `ename` varchar(20) NOT NULL DEFAULT '', `job` varchar(9) NOT NULL DEFAULT '', `mgr` mediumint(8) unsigned NOT NULL DEFAULT '0', `hiredate` date NOT NULL, `sal` decimal(7,2) NOT NULL, `comm` decimal(7,2) NOT NULL, `deptno` mediumint(8) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=500001 DEFAULT CHARSET=utf8;
1.对员工表的信息按照部门,汇总岗位信息的薪资情况。
#常规处理select deptno,sum(if(job = 'dev',sal,null)) dev_sal,sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal,sum(if(job = 'Test',sal,null)) Test_salfrom emp group by deptno
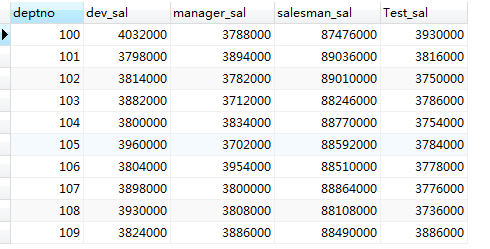
2.如果相对上结果,加上一个汇总展示,如何处理?
#1.使用 union allselect deptno,sum(if(job = 'dev',sal,null)) dev_sal,sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal,sum(if(job = 'Test',sal,null)) Test_salfrom emp group by deptno union all select null ,sum(if(job = 'dev',sal,null)) dev_sal,sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal,sum(if(job = 'Test',sal,null)) Test_salfrom emp#2.使用 rollupselect deptno,sum(if(job = 'dev',sal,null)) dev_sal,sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal,sum(if(job = 'Test',sal,null)) Test_salfrom emp group by deptno with rollup;
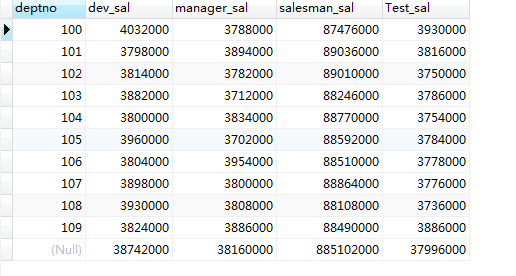
存在问题:
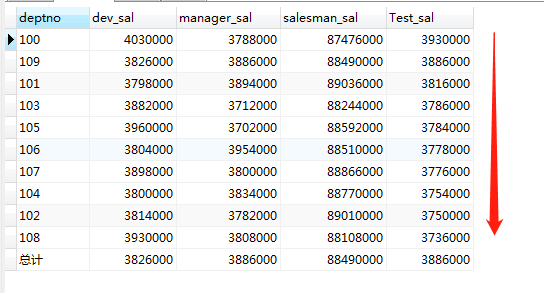
1. 这个记录没有出现总计两个字,怎么实现呢? 使用 ifnull()函数 (有坑)
#有坑版select ifnull(deptno,'汇总') deptno,sum(if(job = 'dev',sal,null)) dev_sal,sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal,sum(if(job = 'Test',sal,null)) Test_salfrom emp group by deptno with rollup;#为什么说有坑? 如果deptno 本身为null ,那么以上查询将会出现多个汇总行。#填坑版 (使用双层ifnull判断 or 将字段定义为not null)select ifnull(deptno,'汇总') deptno,dev_sal,manager_sal,salesman_sal,Test_sal from (select ifnull(deptno,'空城(默认)') deptno,sum(if(job = 'dev',sal,null)) dev_sal,sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal,sum(if(job = 'Test',sal,null)) Test_salfrom emp group by deptno ) a group by deptno with rollup;

2.如果想对其中一列进行排序如何处理?使用order by field()处理
#天真的处理方式select ifnull(deptno,'空城(默认)') deptno,sum(if(job = 'dev',sal,null)) dev_sal,sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal,sum(if(job = 'Test',sal,null)) Test_salfrom emp group by deptno with rollup ORDER BY Test_sal ;#结果报错: Incorrect usage of CUBE/ROLLUP and ORDER BY#原因:MySQL 虽然提供了 group by with rollup 函数进行group by 字段的汇总,but 与 order by 互斥,不能同时用#正确方式 使用order by field()#根据测试岗位的Test_sal薪资降序排列 总计置于底部 =>可以把上面代码当成一个子表嵌套 结合 order by field()自定义函数实现 select *from ( select ifnull(deptno,'总计') deptno,dev_sal,manager_sal,salesman_sal,Test_sal from ( select ifnull(deptno,'空城(默认)') deptno,sum(if(job = 'dev',sal,null)) dev_sal, sum(if(job = 'manager',sal,null)) manager_sal,sum(if(job = 'salesman',sal,null)) salesman_sal, sum(if(job = 'Test',sal,null)) Test_sal from emp group by deptno )a group by deptno with rollup) b ORDER BY FIELD(b.deptno,'总计'),b.Test_sal DESC;